
Our aim at ZOOZ is to help merchants grow globally, by allowing them to manage and optimize multiple payment providers in one place through a single API. As a PaaS company which provides an API to the payments world, we wanted to rebuild our system to be scalable, resilient, and fault tolerant.
Towards the end of 2016, PaymentsOS was born, and we began to rewrite our entire system from scratch. We took a monolithic system and dismantled it into small pieces. We implemented our system with a microservice architecture and followed the twelve-factor app methodology.
Up to today, we have more than 100 different microservices that comprise our system, each deployed multiple times to different zones to ensure high availability and scalability. Most of the services are written in Node.js, but some are written in Scala, Java and Go. We use Linkerd as a service mesh, Cassandra as a database, and DC/OS as our docker orchestration platform.
Our testing strategy was micro-based, where each team mainly focused on testing the most critical components in isolation, but never tested the entire system as a whole.
At the beginning of 2018, when traffic started to increase dramatically, we decided that it’s time to test the performance of the PaymentsOS platform as a fully integrated system. This will ensure that we can meet our required SLA to our clients.
The first step in testing PaymentsOS as a system, was to decide on a framework that will help us write tests which mimic our customers’ flows, run them in distributed runners, and generate test reports. We chose to build our own framework, Predator. After a month of developing, we were ready to start testing the system, and just like in every type of tests, what we found was not what we expected.
In this blog, I’m going to write about our journey of optimizing a platform which consists of more microservices than engineers, and where an average request from a client goes through 10 microservices before finally returning a response to the client.
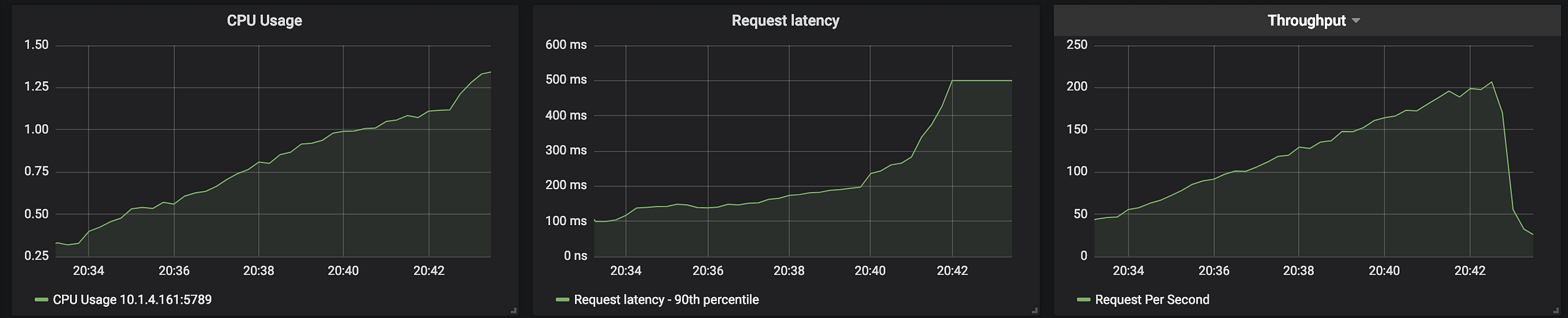
Don’t reach 90% CPU
Node.js runs the code in the event loop. While it’s great for scenarios that run many small tasks that depend on I/O, it fails when its CPU is fully utilized.
To demonstrate this, we ran a simple test using Predator. We ran a 15 minute performance test that started with an arrival rate of 100 RPS and with a ramp up to 250 RPS by the end of the test. We can see that the CPU usage grows linearly while the request latency grows exponentially at the moment the CPU reaches 90%. This growth in request latency is not surprising because when the CPU is so intensely used, the event loop is extremely slow. At high CPU loads, the Node.js event loop is competing with the V8 garbage collector over CPU time. This will result in drastic performance degradation.
DNS Caching and Keep-Alive
Whenever a microservice sends an HTTP request to another microservice by using the target’s DNS address, a connection is initiated. The client translates this DNS record to an IP address by doing DNS resolution.
In the PaymentsOS external API, a single request can trigger the DNS server to perform 10 DNS resolution requests (as an average API call travels between 10 different microservices in our system). With 1,000 RPS to the external API, this would result in 10,000 DNS resolutions. We had to release pressure from the DNS server.
There are many solutions to this issue, some are caching DNS records on the operating system level or the application level. In our Node.js projects we use request.js module to fire http requests, which allows specifying
forever:true to keep sockets alive between requests. In order to illustrate how this improved our system’s results, we ran the same test twice, once with keep-alive and once without. The improvement in performance is dramatic: 2 seconds vs 95ms.

Logs and JSON.stringify() are Dangerous
Lets take a look at the next example:
const bigJson = {...};
const bunyan = require('bunyan');
const logger = bunyan.createLogger({name: 'demo'});function log(message) {
logger.trace(JSON.stringify(message));
}
function foo() {
for (let i=0; i<100000; i++) {
log(bigJson);
}
}
foo();
The logger.trace() is going to be called in each iteration even if the log level is above trace. The performance penalty depends on the evaluation of the parameters be sent to logger.trace().
In the example above the log function is not async anymore. JSON.stringify() is synchronous and is a super expensive function. The above code execution takes a few seconds (depending on the complexity and the size of the bigJson object).
There are two lessons we can take:
1.The calls to the logger happen regardless of the log level you set. If there is a heavy operation when writing the log, check your current log level and call the logger only if it’s relevant.
2. Try to avoid JSON.stringify().
1.The calls to the logger happen regardless of the log level you set. If there is a heavy operation when writing the log, check your current log level and call the logger only if it’s relevant.
2. Try to avoid JSON.stringify().
V8 Garbage Collector
Usually processes running on dockers have trouble understanding the actual memory limit allocated to them in the docker container, and the V8 engine is not any different. This results in “Out of Memory Exceptions” because the garbage collector was not invoked as the node process thinks it got more memory to use. The exception looks like this:
This will limit the max heap size to 256mb and enforce GC to work when getting anywhere near that allocation.
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memoryThe fix in Node.js is quite simple, with the flag —— max-old-space-size the application will start cleaning the heap when it reaches this limit. In our Dockerfiles we use the CMD which looks like this:CMD [ “node”,” — max_old_space_size=256",”./src/app.js” ].This will limit the max heap size to 256mb and enforce GC to work when getting anywhere near that allocation.
Stay native
Moment.js is a an example of a mature library for Node.js with more than 40k stars. While it’s a really useful package, there are some performance penalties that can occur when working with big sets.
In the next example we are going to compare dates comparison, between Moment.js and native Node.
const moment = require('moment');
const today = new Date();
const weekAgo = new Date(today.getDate()-7);
const loops = 999999;
function isBeforeMoment(x, y) {
for (let i = 0; i < loops; i++) {
moment(x).isBefore(y);
}
}
let startTime = Date.now();
isBeforeMoment(moment(today), moment(weekAgo));
console.log(`Moment took: ${Date.now() - startTime} ms`);
function isBeforeNative(x, y) {
for (let i = 0; i < loops; i++) {
x.getTime() < y.getTime();
}
}
startTime = Date.now();
isBeforeNative(today, weekAgo);
console.log(`Native took: ${Date.now() - startTime} ms`);Output:
Moment took: 950 ms
Native took: 3 ms
The result difference is insane, native is 30x times faster than Moment.js. This is one of many examples regarding Moment.js performance flooding. My suggestion is to stay native (javascript/Node) as long as you can.
Today, many functionalities that were once unique to common modules like Lodash and Underscore can be found in native Node libraries. It will also avoid adding possible security vulnerabilities to your code from third-party dependencies.
Today, many functionalities that were once unique to common modules like Lodash and Underscore can be found in native Node libraries. It will also avoid adding possible security vulnerabilities to your code from third-party dependencies.
Beware of async/await
While async/await is great syntactic sugar, it can slow down your application’s response time by not taking advantage of the non blocking I/O in Node.
function getCarBuyer(ms) {
console.log('inside getCarBuyer');
return new Promise(resolve => setTimeout(() => {
console.log('got buyer');
resolve({name: 'niv'})
}, ms));
}
function getCarSeller(ms) {
console.log('inside getCarSeller');
return new Promise(resolve => setTimeout(() => {
console.log('got seller');
resolve({name: 'manor'})
}, ms));
}
async function sellCar() {
let carSeller = await getCarSeller(50);
let carBuyer = await getCarBuyer(50);
console.log(`selling car to ${carBuyer.name} from ${carSeller.name}`);
}
sellCar();Output:
inside getCarSeller
got seller
inside getCarBuyer
got buyer
selling car to niv from manor
In the example, getCarBuyer doesn’t depend on getCarSeller and there is no reason to wait for the first action to finish. It’s possible to use Promise.all(), but I prefer doing it this way:
function getCarBuyer(ms) {
console.log('inside getCarBuyer');
return new Promise(resolve => setTimeout(() => {
console.log('got buyer');
resolve({name: 'niv'})
}, ms));
}
function getCarSeller(ms) {
console.log('inside getCarSeller');
return new Promise(resolve => setTimeout(() => {
console.log('got seller');
resolve({name: 'manor'})
}, ms));}
async function sellCar() {
let carSellerPromise = getCarSeller(60);
let carBuyerPromise = getCarBuyer(50);
let buyer = await carBuyerPromise;
let seller = await carSellerPromise;
console.log(`selling car to ${buyer.name} from ${seller.name}`);
}
sellCar();Output:
inside getCarSeller
inside getCarBuyer
got buyer
got seller
selling car to niv from manor
You can notice that now both promises are fired simultaneously, but before proceeding to the next step when we need both of the results we wait.
How to find your bottlenecks
Below is a simple, step by step process that we take here at ZOOZ to identify and solve our performance issues.
1. Use A Performance Framework
Overall system performance and reliability are some fundamental concepts that need to be taken into account when designing a high capacity API. With CI/CD becoming a common deployment methodology, deployments to production are a constant occurrence. Unless you test your system frequently you won’t find the bottlenecks and regression in time, but rather when you are already deep into the problem.
2. Harvest Metrics
There is no easy way to find out which services in your system may be lagging. Collecting metrics from each component in the system and showing them graphically in centralized dashboards can dramatically help identify the bottle necks. To achieve this at Zooz, we use Prometheus as our time series database and Grafana as our graphing solution. In PaymentsOS, each microservice exposes a metrics endpoint that is scraped by Prometheus and displayed in Grafana. This allows us to get an overall snapshot of our system and its microservices in every given moment. The important metrics for us are: CPU/Memory, instance count, request latency by percentile, endpoint and status code, and requests throughput per second.
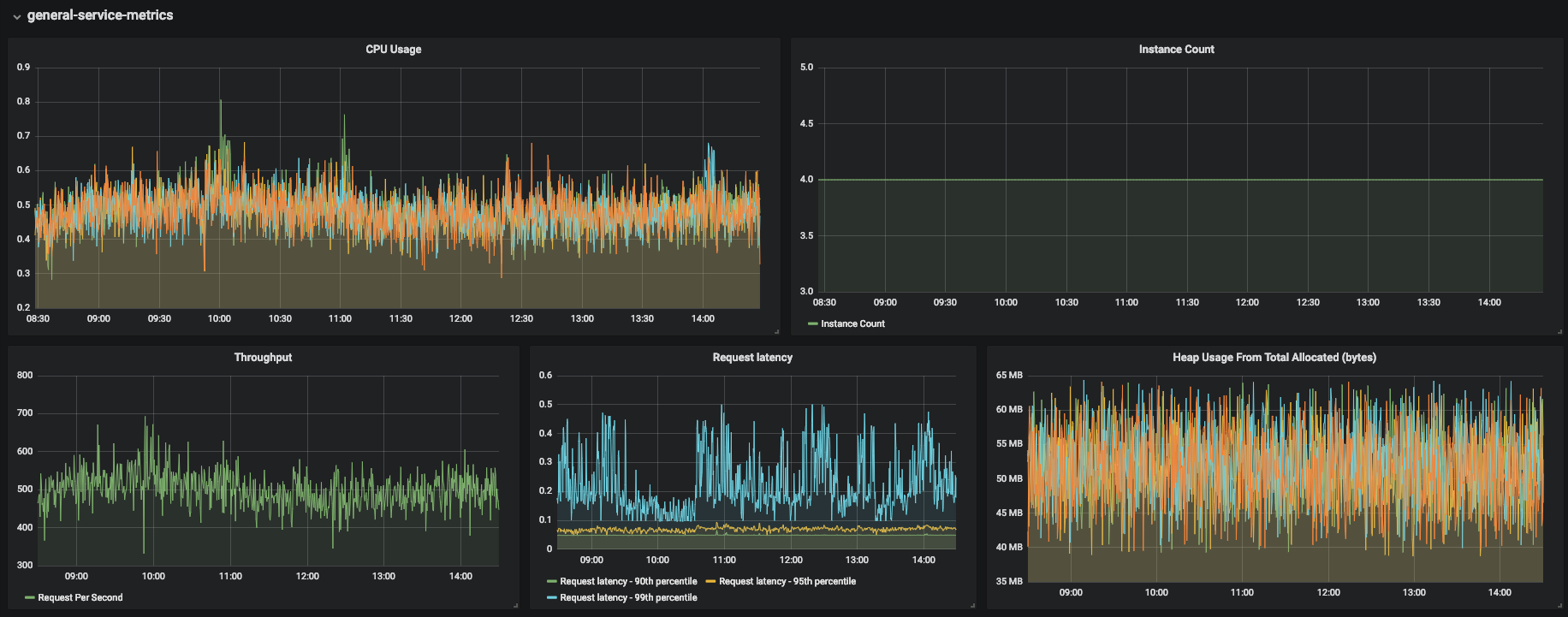
3. Use CPU Profiler
After running the performance tests and correlating with the metrics, you should be able to pinpoint which services behave slower than expected. One of the advantages when writing microservice is that they are much smaller than a monolith service, which can help you find the performance issues much faster. To find exactly which parts in our code are problematic, profilers are essential. For example, recording the cpu profiling is a very efficient method to identify the cpu power and which functions consume most of the CPU.
In the example below, we can see that Moment.js is responsible for using 86% of the cpu by itself.
After refactoring the code to be more efficient, it’s time to start the process again by re-running the performance tests and comparing to past results.
Recently, we developed an open source performance testing framework for us, called Predator, which takes care of the full lifecycle of running performance tests. Using Predator, you are able to load your services with the wanted load to see if they are performing as expected. To read more about Predator, its features, and its deployment integrations read here.
